Autor: João Victor Assaoka Ribeiro
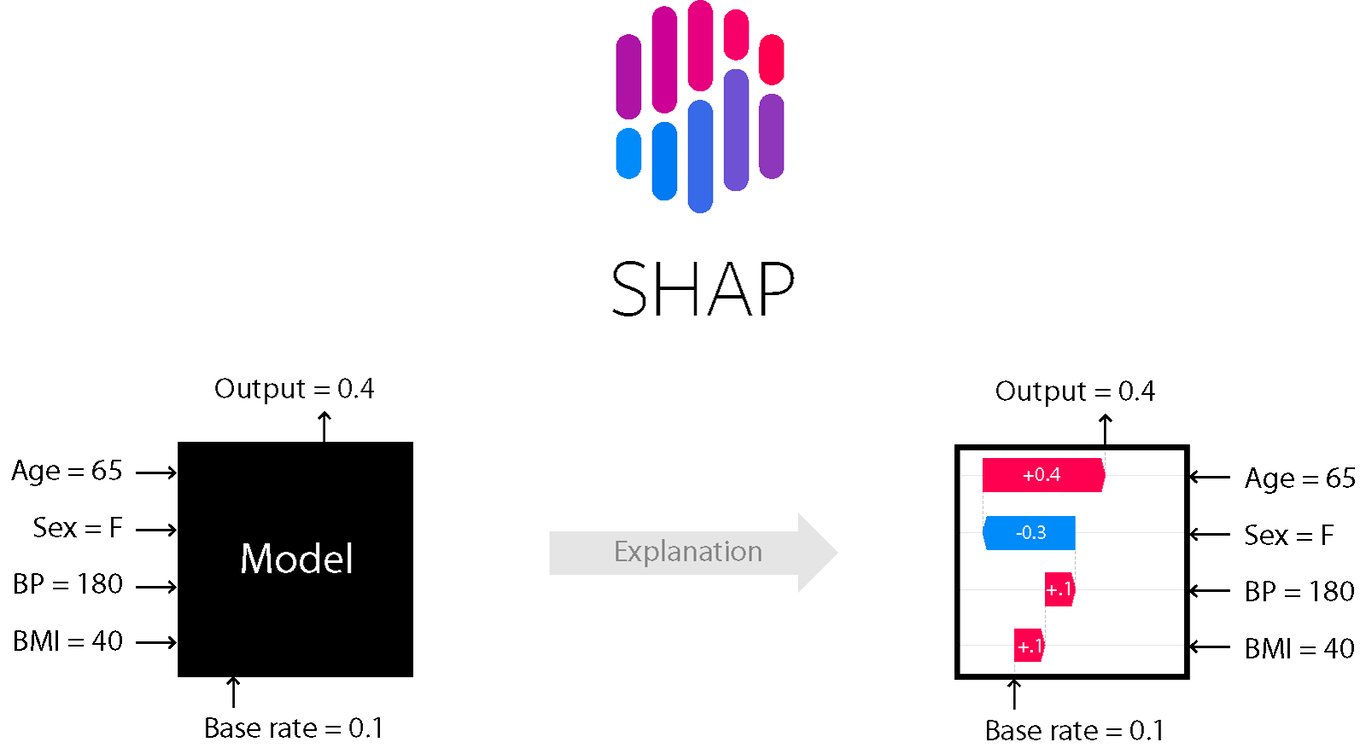
A manutenção preditiva está se tornando cada vez mais sofisticada com o uso de machine learning, mas com essa sofisticação vem um desafio: como entender por que nosso modelo está fazendo determinadas previsões? É aqui que entra o SHAP (SHapley Additive exPlanations), uma técnica poderosa para explicar as previsões de qualquer modelo de machine learning.
Intuição do Funcionamento
Imagine que você está jogando futebol com seus amigos e, após a partida, vocês querem determinar quanto cada jogador contribuiu para a vitória do time. Alguns jogadores jogaram a partida inteira, outros só meio tempo, e alguns fizeram jogadas decisivas. Como calcular a contribuição justa de cada um?
O SHAP resolve esse problema usando um conceito da teoria dos jogos chamado Valores de Shapley. No nosso contexto de manutenção preditiva, em vez de jogadores, estamos avaliando quanto cada característica (temperatura, vibração, pressão, etc.) contribui para a previsão final do modelo.
Como o SHAP funciona?
O SHAP calcula a contribuição de cada característica considerando todas as possíveis combinações de características. Por exemplo:
Qual seria a previsão usando apenas a temperatura?
E usando temperatura + vibração?
E usando todas as características exceto temperatura?
Ao comparar essas combinações, o SHAP consegue determinar o impacto real de cada característica na previsão final.
Implementação Comentada
Vamos implementar o SHAP usando Python e aplicá-lo a um modelo de manutenção preditiva. Utilizaremos o conjunto de dados de uma bateria, onde queremos prever a vida útil da bateria com base em várias características (temperatura, corrente, etc.).
Passo 1: Instalação e Importação das Bibliotecas
# Instalando as bibliotecas necessárias
!pip install shap xgboost pandas numpy matplotlib
# Importando as bibliotecas
import shap
import xgboost as xgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_splitPasso 2: Preparação dos Dados e Treinamento do Modelo
# Carregar os dados
arquivo = '/content/drive/MyDrive/Datasets Públicos/Battery_RUL.csv' # Endereço do arquivo .csv
df = pd.read_csv(arquivo)
# Separar features e target
X = df.drop('RUL', axis=1)
y = df['RUL']
# Dividir em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Criar e treinar um modelo (vamos usar XGBoost como exemplo)
model = xgb.XGBRegressor(n_estimators=500, random_state=42)
model.fit(X_train, y_train)Passo 3: Calculando os Valores SHAP
# Criar o explainer SHAP
explainer = shap.Explainer(model.predict, X_test)
# Calcular os valores SHAP e encapsulá-los em um objeto Explanation
shap_values = explainer(X_test)Passo 4: Criando o Gráfico Beeswarm
O gráfico Beeswarm é excelente para visualizar o impacto geral das características no modelo.
# Gerar o gráfico beeswarm
shap.plots.beeswarm(shap_values)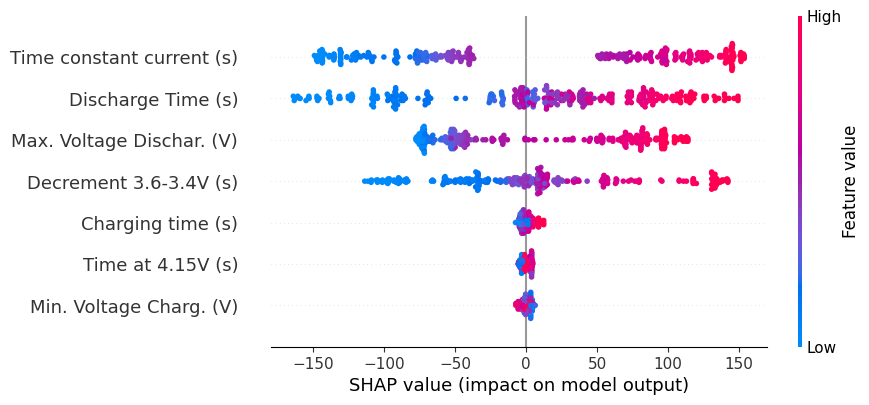
O gráfico Beeswarm mostra:
No eixo y: as características ordenadas por importância
No eixo x: o impacto SHAP (quanto maior o valor absoluto, maior o impacto)
Cores: vermelho indica valores altos da característica, azul indica valores baixos
Passo 5: Criando o Gráfico Waterfall
O gráfico Waterfall é ótimo para entender uma previsão específica.
# Escolher uma amostra específica para explicar
exemplo_idx = 0
# Criar o gráfico Waterfall
shap.plots.waterfall(shap_values[exemplo_idx]) 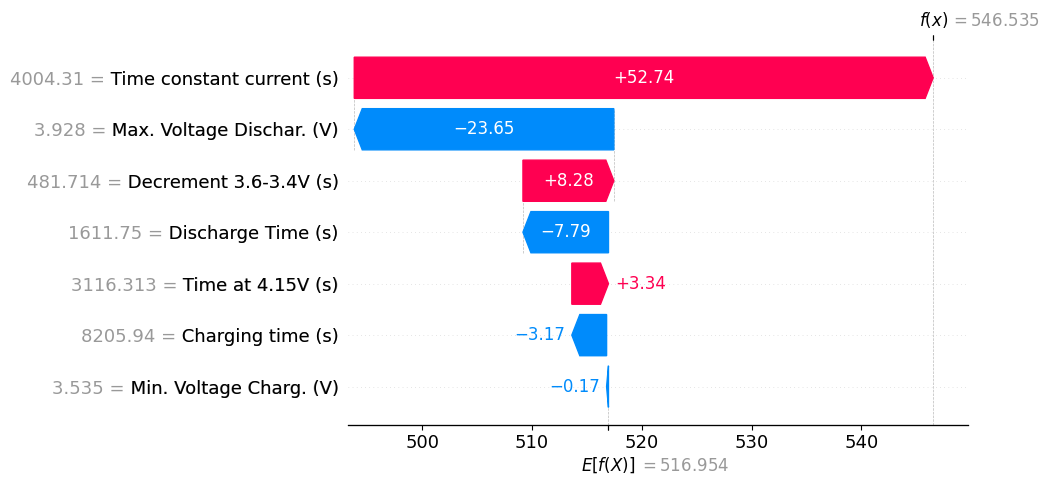
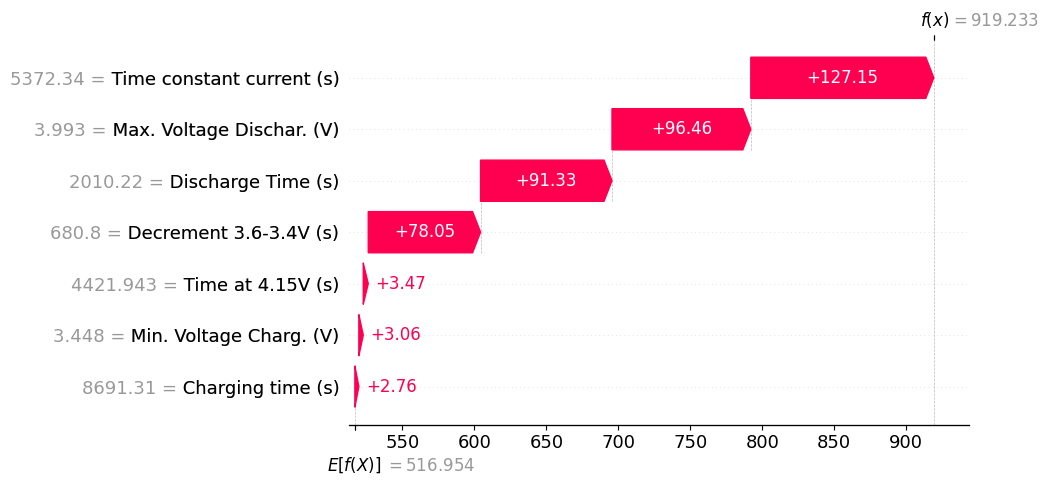
O gráfico Waterfall ilustra como cada característica contribui para ajustar a previsão do valor base (neste caso, 516,954) até o valor final. As barras vermelhas representam as características que aumentam a previsão, enquanto as barras azuis representam as características que diminuem a previsão.
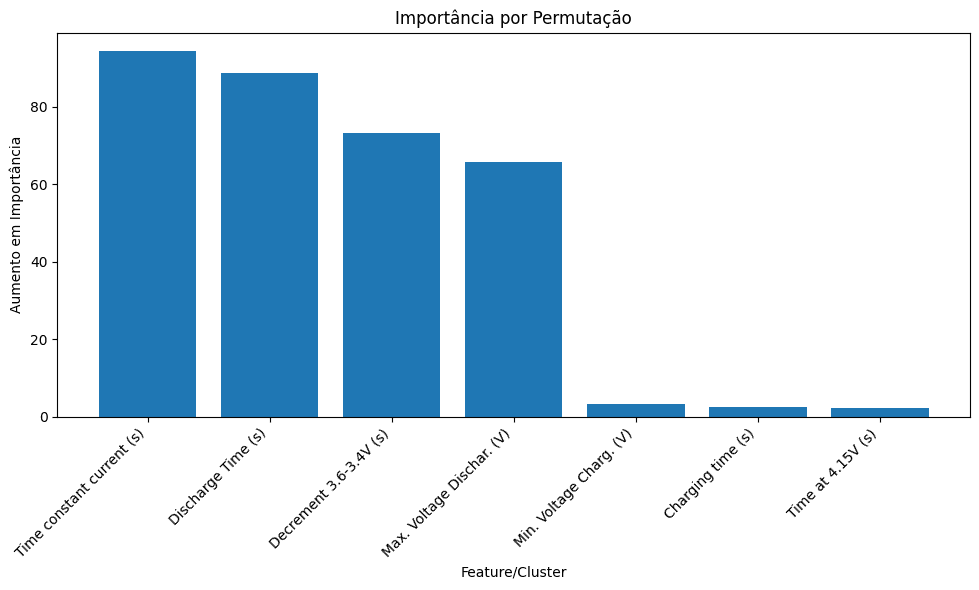
Passo 6: Ranking das Características
importancias = pd.DataFrame({
'Caracteristica': X_test.columns,
'Média': np.abs(shap_values.values).mean(0), # Accessing the numerical values using .values
'Mediana': np.median(np.abs(shap_values.values), axis=0), # Applying np.median to the array
'Desvio Padrão': np.abs(shap_values.values).std(0) # Accessing the numerical values using .values
})
importancias = importancias.sort_values('Média', ascending=False)
print("Ranking de Importância:")
print(importancias)Aplicações Práticas na Manutenção Preditiva
O SHAP pode ser usado para:
Identificar Indicadores Precoces de Falha
Descobrir quais sensores mostram os primeiros sinais de problemas
Priorizar a instalação de sensores mais relevantes
Otimizar Manutenção
Entender quais condições mais contribuem para a degradação do equipamento
Ajustar parâmetros operacionais para prolongar a vida útil
Validar Conhecimento do Domínio
Permite que especialistas em manutenção validem se o modelo está considerando as características corretas
Ajuda a identificar discrepâncias entre o conhecimento do domínio e o modelo
Conclusão
O SHAP é uma ferramenta poderosa para tornar os modelos de manutenção preditiva mais transparentes e confiáveis. Os gráficos Beeswarm e Waterfall fornecem visões complementares: enquanto o Beeswarm dá uma visão geral do modelo, o Waterfall permite entender previsões específicas em detalhes.
Você pode experimentar este código no Google Colab. Lembre-se de fazer uma cópia do notebook para seu Drive antes de começar a experimentar.
Caso tenha alguma dúvida, você pode encontrar mais informações na documentação oficial do SHAP.