Autor: João Victor Assaoka Ribeiro
As árvores de decisão são um dos algoritmos mais clássicos em aprendizado de máquina. Elas podem ser aplicadas tanto para problemas de classificação quanto de regressão, o que significa que você pode usá-las para prever tanto categorias (como "precisa de manutenção" ou "não precisa de manutenção") quanto valores numéricos (como a vida útil restante de uma máquina).
A principal ideia por trás das árvores de decisão é bem intuitiva: ela tenta dividir os dados em subconjuntos menores e mais homogêneos, até que todos os subconjuntos tenham resultados similares.
Imagine que você está dividindo um grupo de pessoas com base em características como idade, renda e localização. A árvore de decisão faz exatamente isso, só que automaticamente, escolhendo as melhores "perguntas" (características) para separar os grupos.
Como funcionam as Árvores de Decisão?
Uma árvore de decisão pode ser visualizada como um fluxograma. Ela começa com uma pergunta (nó raiz) e, dependendo da resposta, segue para outras perguntas (nós internos) até chegar a um resultado final (nós folha). Cada caminho da árvore corresponde a uma sequência de decisões.
Aqui está um exemplo:
- Nó Raiz: "A máquina já rodou mais de 1.000 horas?"
- Se sim, faz outra pergunta: "A vibração está acima de 50 Hz?"
- Se não, faz outra pergunta: "A temperatura média está acima de 70°C?"
E assim por diante, até que chegue a uma conclusão da previsão.
No contexto de aprendizado de máquina
A parte de aprendizado de máquina não é a árvore em si, mas sim o algoritmo responsável por encontrar qual regra deve ser utilizada para separar os dados. A maioria dos algoritmos funcionam buscando a característica que mais agregue informações na separação dos dados, ou seja, a característica que mais ajuda a separar corretamente os exemplos.
Por que usar Árvores de Decisão?
Existem várias vantagens em usar árvores de decisão:
1. Facilidade de interpretação: Como as árvores seguem uma estrutura de "se... então...", elas são fáceis de entender e explicar, mesmo para quem não é técnico.
2. Visualização: Você pode facilmente visualizar a árvore, o que ajuda a interpretar como os dados estão sendo processados.
3. Rapidez: As árvores de decisão são rápidas para treinar e fazer previsões, o que é útil quando você quer testar rapidamente diferentes hipóteses.
No entanto, é importante mencionar que árvores de decisão isoladas podem não ser a melhor escolha para problemas mais complexos. Elas tendem a "se ajustar demais" aos dados de treino, o que chamamos de overfitting.
Implementando uma Árvore de Decisão com Python
Agora que entendemos o conceito básico de árvores de decisão, vamos ver como implementá-las na prática usando a biblioteca Scikit-learn, uma das mais populares em aprendizado de máquina.
Vamos usar o DecisionTreeRegressor, que é uma versão das árvores de decisão usada para problemas de regressão (quando queremos prever um valor numérico).
Exemplo: Prevendo a Vida Útil de Máquinas
Neste exemplo, vamos usar uma base de dados em formato .csv, que contém informações sobre uma bateria. Nosso objetivo é prever a vida útil restante da bateria com base nas variáveis disponíveis.
Esse dataset pode ser encontrado no kaggle. Tratamos esse conjunto de dados selecionando apenas a primeira bateria e excluindo a característica Cycle_Index para simplificar o exemplo. Você pode baixar o arquivo aqui.
Passo 1: Instalar e importar as bibliotecas necessárias
# Primeiro, certifique-se de que o Scikit-learn está instalado
!pip install scikit-learn pandas matplotlib
# Agora, importe as bibliotecas que vamos usar
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as pltPasso 2: Carregar e visualizar os dados
# Carregar os dados
arquivo = 'bateria.csv' # Endereço do arquivo .csv
df = pd.read_csv(arquivo)
# Visualizar as 10 primeiras linhas do dataframe
display(df.head(10))Passo 3: Preparar os dados
Agora, vamos separar os dados em variáveis de entrada (x) e saída (y). Em seguida, dividiremos os dados em conjuntos de treino (70%) e teste (30%).
# Separar os dados em variáveis de entrada (x) e saída (y)
alvo = 'vida_util' # Altere para o nome da coluna que você quer prever
x = df.drop(alvo, axis=1)
y = df[alvo]
# Dividir os dados em treino e teste
proporcao_teste = 0.3 # 30% dos dados serão usados para teste
x_treino, x_teste, y_treino, y_teste = train_test_split(x, y, test_size=proporcao_teste, random_state=42)
# Ordenando os índices para facilitar a visualização dos gráficos
x_treino = x_treino.sort_index()
y_treino = y_treino.sort_index()
x_teste = x_teste.sort_index()
y_teste = y_teste.sort_index()
# Exibir o tamanho dos conjuntos de treino e teste
print(f'Tamanho do conjunto de treino: {len(x_treino)}')
print(f'Tamanho do conjunto de teste: {len(x_teste)}')Passo 4: Treinar o modelo
Vamos utilizar o DecisionTreeRegressor para treinar o modelo nos dados de treinamento.
# Inicializar o modelo
modelo = DecisionTreeRegressor(max_depth=3, # Profundidade máxima da árvore (reduz a chance de overfitting)
random_state=42) # Seed para reprodução dos resultados
# Treinar o modelo
modelo.fit(x_treino, y_treino)Passo 5: Fazer previsões
Agora que o modelo está treinado, vamos usá-lo para fazer previsões nos dados de teste. Além disso, vamos calcular o erro médio absoluto (MAE) para avaliar o desempenho do modelo.
# Fazer previsões
y_pred = modelo.predict(x_teste)
# Calcular o erro médio absoluto
mae = abs(y_teste - y_pred).mean()
print(f'Erro médio absoluto: {mae:.2f}')
# Visualizando as previsões
plt.figure(figsize=(10, 6))
plt.plot(y_teste.values, label='Real')
plt.plot(y_pred, label='Previsto')
plt.title(f'Real vs. Previsto - MAE: {mae:.2f}')
plt.legend(loc='upper right')
plt.show()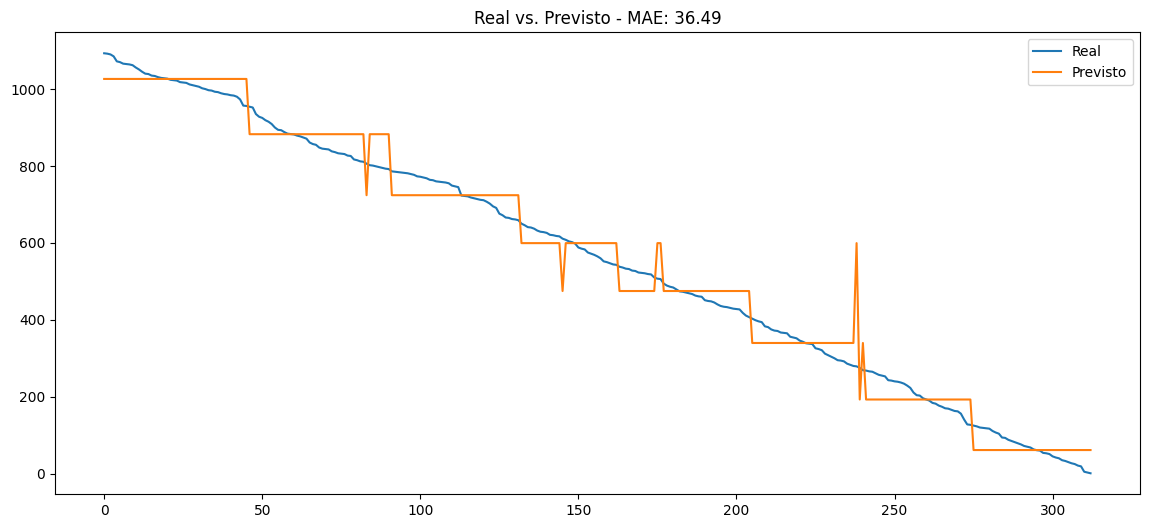
Passo 6: Visualizar a Árvore de Decisão (Opcional)
Podemos visualizar de forma gráfica como a árvore de decisão está tomando as decisões.
from sklearn import tree
plt.figure(figsize=(20, 10))
tree.plot_tree(modelo, # Modelo treinado
filled=True, # Preencher os nós com cores
feature_names=x.columns) # Nomes das variáveis de entrada
plt.show()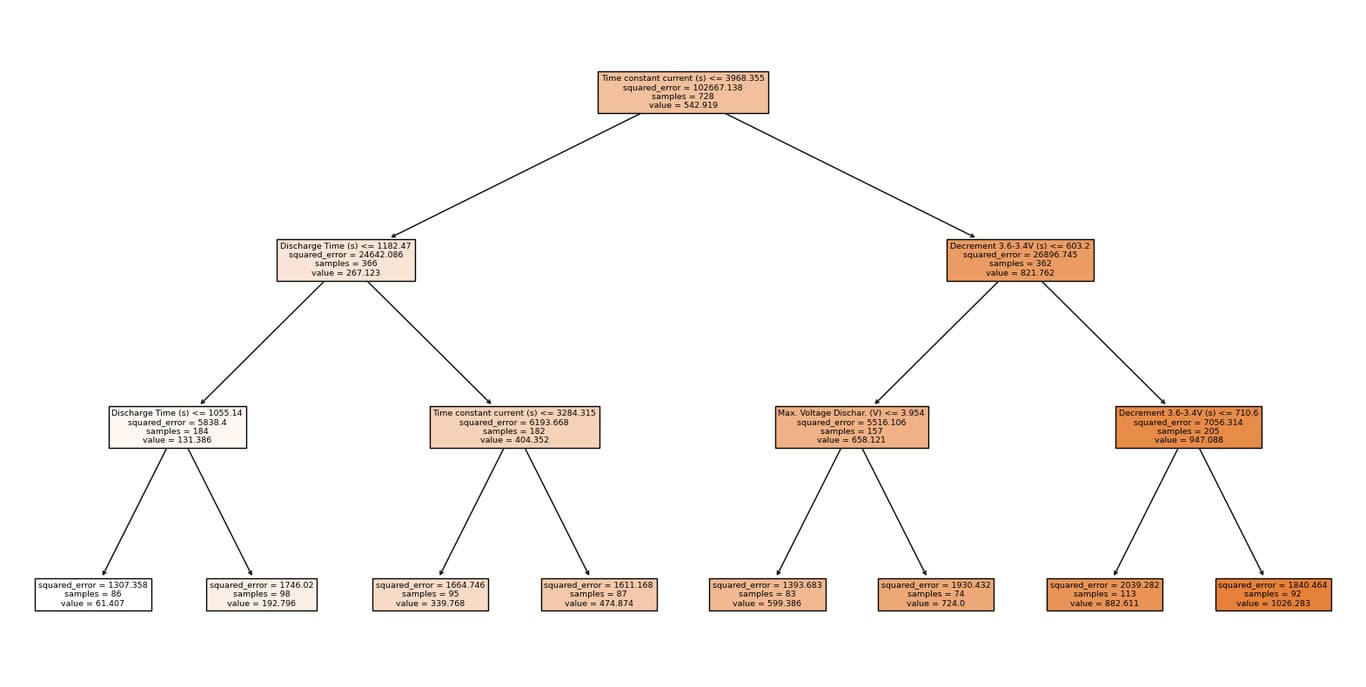
Conclusão
Neste post, vimos o que são árvores de decisão, como elas funcionam e como podemos aplicá-las em problemas de manutenção preditiva usando Python e a biblioteca Scikit-learn. As árvores de decisão são uma ferramenta poderosa e fácil de entender, ideal para quem está começando em aprendizado de máquina.
Você pode experimentar esse código no Google Colab. Faça uma cópia do notebook e adapte-o para seus próprios dados e necessidades. Se tiver alguma dúvida, você pode consultar a documentação oficial do Scikit-learn para obter mais informações ou entrar em contato comigo.